Si vous observez depuis ces derniers jours à travers vos logs, ou le rapport d’exploration de la Google Search Console un pic d’URL finissant par /1000 vous n’êtes pas un cas isolé. Faisons le tour ensemble de ce sujet d’actualité.
Pourquoi vois-je des url /1000 dans mon rapport d’exploration de la Google Search Console ?
Voici un exemple de site dont Google a découvert à partir du 11 janvier une série d’URL se terminant par /1000, chacune de ces URL est au format suivant : https://www.{nomdusite}.com/page.html/1000
Cette capture d’écran est faite depuis le rapport Indexation des pages > Introuvable (404) :
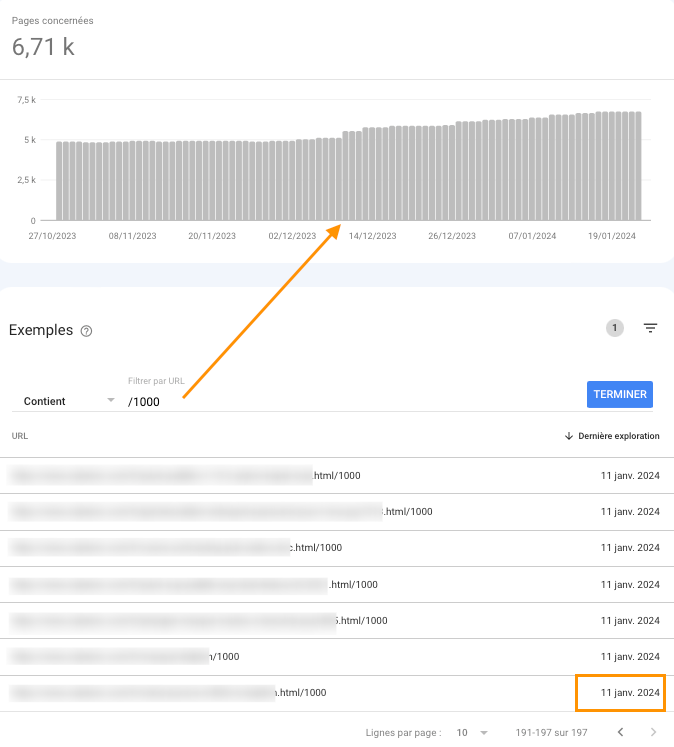
Pourquoi Google tente-t-il d’accéder à ces URL ?
Il s’agit en réalité d’une vague de spam de backlinks provenant de sites qui pratiquent ce que l’on appelle du cloaking (technique permettant de servir un contenu différent en fonction de l’utilisateur). Ici, le contenu servi pour l’internaute renvoie généralement vers des sites adultes, alors que Google a accès à un tout autre contenu (dont des URL comportant un /1000 ou //1000 à la fin et faisant référence au site en question).
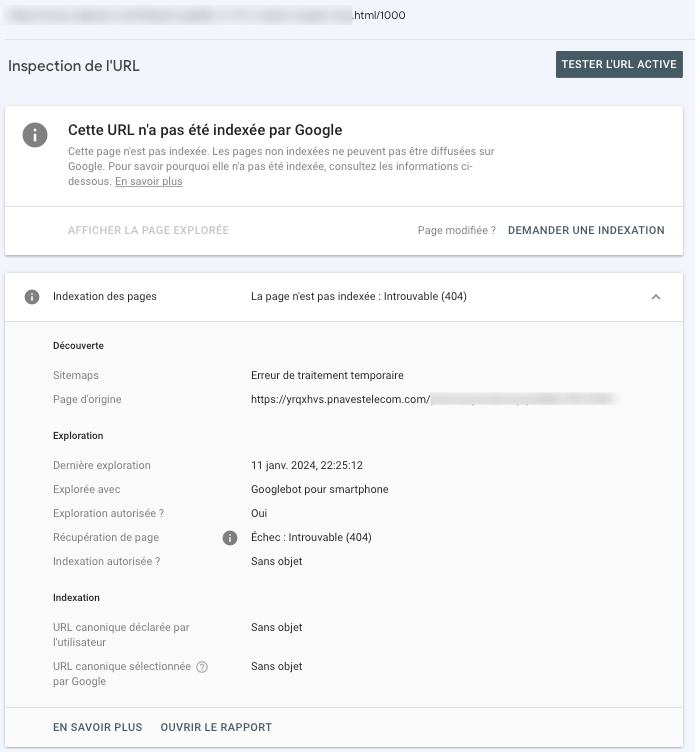
Vous pouvez détecter la source de ces sites en inspectant l’URL en question dans la Search Console :
Voici une capture d’une page du site spammeur dans la version en cache “texte seul” de Google (ici sur une requête américaine) :

Quel impact sur mon site Internet ?
Dans la majorité des cas, cela se soldera par une erreur 404 générée par votre serveur web et donc Google va progressivement se désintéresser de ce type de pages.
Néanmoins, pour des raisons de budget de crawl, il peut être intéressant de bloquer ces types de pages aux moteurs de recherche et ainsi leur éviter de perdre du temps sur ces pages qui n’auront pas de valeur pour l’internaute.
Dans quels cas s’inquiéter ?
D’une manière générale, si la configuration de votre serveur web ne permet pas de générer un code réponse 404, mais une redirection (301, 302) ou pire une réponse 200, cela devient plus problématique.
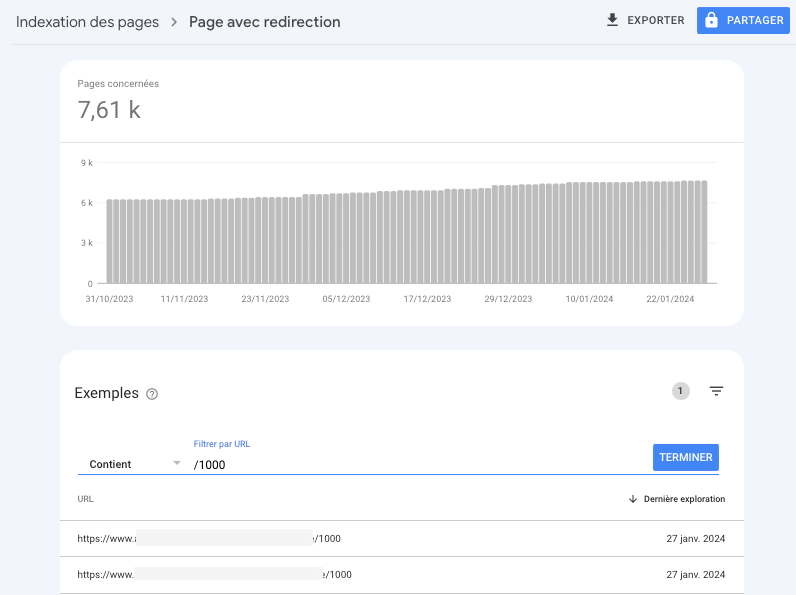
Cas des redirections (301 ou 302) :
Google et les autres moteurs de recherche devront suivre les redirections ce qui va consommer inutilement du budget de crawl.
Pour vérifier si vous êtes dans ce cas, rendez-vous dans le rapport Indexation > Page avec redirection :
Cas des réponses (200) :
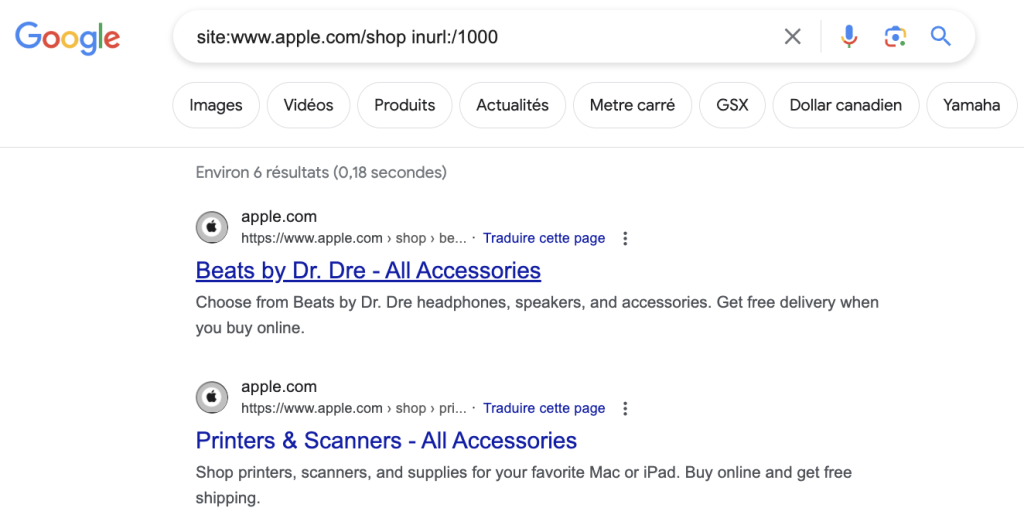
Si la page est indexable (pas de meta robots noindex par exemple ou canonical), le risque est de créer du contenu dupliqué et donc potentiellement dégrader votre visibilité.
Exemple du site Apple.com dont certaines URL de la boutique s’indexent avec le /1000 à la fin :
La solution technique facilement applicable :
Si vous êtes soucieux pour votre budget de crawl et que vous soyez dans l’incapacité de pouvoir générer un code réponse 404 sur cette typologie d’URL, nous vous conseillons de bloquer l’accès à toutes les URL terminant par /1000 via votre fichier robots.txt en ajoutant la directive suivante :
Disallow: */1000$Attention tout de même à bien vérifier que votre site ne possède aucune “vraie” URL terminant par /1000 au risque de bloquer l’accès à une page pertinente.
